
Array 클래스
public 생성자가 하나만 있다. 이 생성자는 다음의 두 인자를 받는다.
- Int 타입의 size
- init, 즉 (Int) -> T 타입의 람다
val squares = Array(5) { i -> i*i }
for( (index, item) in squares.withIndex()) {
println("$index" + ": " + "$item")
}
listOf
변경 불가능한 컬렉션 (읽기 전용)

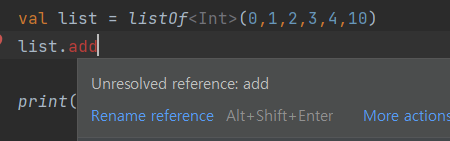
mutableListOf
변경 가능한 컬렉션 (읽기/쓰기 가능)

변경 가능한 컬렉션(리스트, 세트, 맵)이 있을 때 해당 컬렉션의 읽기 전용 버전을 생성하고 싶다.
1. toList (toSet, toMap 메소드 사용)

2. 레퍼런스에 가변 리스트를 할당
빨간색 박스처럼 toList 를 사용하면 가변 리스트를 복사한 독립된 객체가 생성되기 때문에,
이후, 원본 가변리스트의 값을 변경하더라도 그 영향을 미치지 않는다.
초록색 박스는 읽기전용 타입인 List 타입의 레퍼런스에 원본 가변리스트를 할당하였다.
이후, 원본 가변리스트의 값을 변경하게 되면 레퍼런스 하고 있기 때문에 값에 영향을 미치게 된다.

컬렉션이 빈 경우 기본값 리턴하기
>> ifEmpty 메소드 사용
* 아래 사용된 map, filter 함수는 아래에 따로 설명하겠습니다.
fun nameOfProductOnSale(products: List<Product>) =
products.filter { it.onSale }
.map { it.name }
.ifEmpty { listOf("None") } //빈 컬렉션에 기본리스트를 제공 //출력: None
.joinToString(separator = ", ")
//.ifEmpty { listOf("None") } //빈 문자열에 기본 문자열을 제공 //출력: [None]
val products = ArrayList<Product>()
products.add(Product("Apple", false))
products.add(Product("Mango", false))
products.add(Product("WaterMelon", false))
println(nameOfProductOnSale(products))
data class Product (val name: String, val onSale: Boolean = false)
값이 주어졌을 때, 주어진 값이 특정 범위 안에 들면 해당 값을 리턴하고, 그렇지 않다면 범위의 최소값 또는 최대값을 리턴한다.
>>kotlin.range의 coerceIn 함수 사용
val range = 70..90
println(50.coerceIn(range)) //70
println(80.coerceIn(range)) //80
println(100.coerceIn(range)) //90
컬렉션을 윈도우로 처리하기
컬렉션을 같은 크기로 나누고 싶다면 chunked 함수를 사용
val range = 1..10
val chunk = range.chunked(3) //[[1,2,3],[4,5,6],[7,8,9],[10]] ; chunk의 타입은 List<List<T>> 이다.
println(range.chunked(3){it.sum()}) //[6, 15, 24, 10]
windowed
- windowed(size, size, partialWindows = false)
-size : 각 윈도우에 포함될 원소의 개수
-size : 각 단계마다 전진할 원소의 개수 (기본 1개)
-partialWindows : 나뉘어 있는 마지막 부분이 윈도우에 필요한 만큼의 원소 개수를 갖지 못한 경우, 해당 부분을 그대로 유지할지 여부를 알려주는 불리언 값 (기본 flase) - chunked 함수는 windowed(chunked인자, chunked인자, true) 인 특별한 case의 windowed 함수다.
val windowed = range.windowed(3,2) //[[1, 2, 3], [3, 4, 5], [5, 6, 7], [7, 8, 9]]
println(range.windowed(3,2){it.sum()}) //[6, 12, 18, 24]
아래부터 공통적으로 사용될 collection data입니다.
data class Product (val name: String, val price: Int, val onSale: Boolean = false)
val products = ArrayList<Product>()
products.add(Product("Tomato", 3000,false))
products.add(Product("Apple", 3000,false))
products.add(Product("Mango", 50000,false))
products.add(Product("Pear", 25000,false))
products.add(Product("WaterMelon", 25000, false))
products.add(Product("Strawberry", 25000,false))
정렬하기
sortedWith 와 compareBy 메소드를 사용한다.
val products1 = products.sortedWith( //리턴타입: List<T>
compareBy({it.price}, {it.name}) //가격정렬을 먼저 하고, 그 기준으로 다시 이름 정렬을 한다.
)
products1.forEach{println(it)}
//출력
Product(name=Apple, price=3000, onSale=false)
Product(name=Tomato, price=3000, onSale=false)
Product(name=Pear, price=25000, onSale=false)
Product(name=Strawberry, price=25000, onSale=false)
Product(name=WaterMelon, price=25000, onSale=false)
Product(name=Mango, price=50000, onSale=false)
compareBy 메소드는 Comparator를 생성하고, sortedWith 함수는 Comparator 를 인자로 받는다.


이전 비교 후에 새로운 비교를 적용하는 thenBy 함수를 사용해 Comparator 를 생성할 수 있다.
val comparator = compareBy<Product>(Product::price)
.thenBy(Product::name)
products.sortedWith(comparator)
.forEach{println(it)}
filter
filterIsInstance 함수
val myList = listOf("a", LocalDate.now(), 1,2,3, "b")
val strings = myList.filterIsInstance<String>()
println(strings.joinToString(separator = ", "))
filter 함수
주어진 람다에 원소를 넘겨서 람다가 true를 반환하는 조건을 만족하는 원소만 필터링하는 기능
val intList = listOf(1,2,3,4,5)
println(intList.filter{it > 3}) //[4,5]println(products.filter{it.price >= 25000})
map
map 함수는 각 원소를 원하는 형태로 변환하는 기능을 하며, 변환한 결과를 모아서 새 컬렉션을 만듭니다.
결과는 원본 리스트와 원소 개수는 같지만, 각 원소는 주어진 람다(함수)에 따라 변환된 새로운 컬렉션입니다.
val intList = listOf(1,2,3,4,5)
println(intList.map{it * it}) //[1, 4, 9, 16, 25]
println(products.filter{it.price > 30000}.map{it.name}) //name list로 변환
람다의 멤버 참조 : 괄호 안에 멤버 프로퍼티를 넣는다
println(products.filter{it.price > 30000}.map(Product::name)) //람다의 멤버 참조로 변환
가장 가격이 비싼 과일의 이름을 알고 싶다면?
val maxPrice = products.maxByOrNull { it.price }?.price
println(products.filter{it.price == maxPrice}.map(Product::name))
컬렉션 조건 함수 - all, any, count, find

println(products.all{it.price == maxPrice}) //false
println(products.any{it.price == maxPrice}) //true
println(products.count{it.price == maxPrice}) //1
println(products.find{it.price == maxPrice}) //Product(name=Mango, price=50000, onSale=false)
//람다에 사용되는 조건문이 반복될 경우, 람다를 변수로 지정해서 파라미터로 사용 가능
val isMaxPrice = { p: Product -> p.price == maxPrice }
println(products.all(isMaxPrice)) //false
* size vs count
count 함수가 있다는 사실을 잊어버리고, 컬렉션을 필터링한 결과의 크기를 size로 가져오는 경우가 종종 있습니다.
println(products.filter{it.price >= 25000}.size) //4
하지만, 이렇게 처리하면 조건을 만족하는 모든 원소가 들어가는 중간 컬렉션이 생겨버리게 됩니다.
반면에, count는 조건을 만족하는 원소의 개수만을 추적할 뿐, 원소를 따로 저장하지는 않기 때문에,
count가 훨씬 더 효율적이라고 할 수 있습니다.
groupBy
컬렉션의 모든 원소를 어떤 특성에 따라 여러 그룹으로 나누고 싶은 경우가 있습니다.
결과는 아래와 같은 맵(Map)입니다.
- Key : 원소를 구분하는 특성 (예제에서는 price)
- Value : Key 값에 따른 각 그룹 리스트 (예제에서는 Product 객체 리스트)
println(products.groupBy { it.price })
//{3000=[Product(name=Tomato, price=3000, onSale=false), Product(name=Apple, price=3000, onSale=false)], 50000=[Product(name=Mango, price=50000, onSale=false)], 25000=[Product(name=Pear, price=25000, onSale=false), Product(name=WaterMelon, price=25000, onSale=false), Product(name=Strawberry, price=25000, onSale=false)]}가격으로 그룹을 나누었을 때 리턴되는 결과는 Map<Int, List<Product>>입니다.
'Kotlin' 카테고리의 다른 글
| enum class, sealed class (0) | 2022.03.31 |
|---|---|
| sequence (0) | 2022.03.27 |
| reduce, fold (0) | 2022.03.26 |
| lateinit, lazy (0) | 2022.03.26 |
| Scope 함수(범위 지정 함수 - apply, with, let, also, run) (0) | 2022.03.26 |